Colectivitatea sau populația statistică reprezintă totalitatea elementelor sau a manifestărilor de aceeași natură, asupra cărora se efectuează cercetarea.
Putem reține și o altă definiție a populației statistice, ca fiind întregul set de unități de interes pentru analiza datelor.
Populația poate fi formată din persoane, obiecte, evenimente sau orice altă entitate relevantă pentru un studiu.
Exemple: totalitatea angajaților unei companii sau toți locuitorii unui oraș.
Colectivitatea supusă cercetării poate fi totală și se numește cercetare exhaustivă, atunci când se fac înregistrări referitoare la toate elementele care formează obiectul studiului, sau parțială, când se utilizează un eșantion, prin care se fac înregistrări referitoare numai la o parte din această colectivitate.
Eșantionul: este un subset reprezentativ extras din populație pentru a efectua analize. Este folosit pentru a face inferențe despre populație, reducând costurile și timpul necesare colectării datelor.
Exemplu: Un sondaj efectuat pe 500 de angajați dintr-o companie mare, cu 25000 de angajați.
Alegerea unui eșantion reprezentativ este crucială pentru a obține rezultate valide. Tehnicile de eșantionare, cum ar fi eșantionarea aleatorie simplă, stratificată sau cluster, sunt esențiale pentru a reduce erorile de eșantionare.
3.1.2 Unitate statistică
Elementele care compun populația statistică se numesc unități statistice sau unități de observare. Unitatea statistică sau unitatea de observare este cea mai mică entitate despre care se colectează informații. Unitățile statistice reprezintă mulțimea numărabilă de elemente care compun colectivitatea statistică.
De exemplu, unitatea statistică a unei cercetări referitoare la veniturile populației poate fi gospodăria sau persoana. Unitatea statistică a unei cercetări privind calitatea producției este produsul finit, semifabricatul sau piesa căreia i se testează caracteristicile.
Unitățile statistice pot fi simple sau complexe. Cele complexe sunt formate din mai multe unități simple. O astfel de unitate este gospodăria1. Unitățile pe care se realizează cercetarea salariilor sunt, de asemenea unități complexe: unitățile economice la care se face înregistrarea datelor.
3.1.3 Caracteristici ale unității statistice
Fiecare element al colectivității este purtătorul cel puțin a unei caracteristici supuse observării statistice. Caracteristica statistică reprezintă acea proprietate/însușire care este comună tuturor unităților unei colectivități statistice cercetate.
Caracteristicele statistice poartă numele și de variabile.
O variabilă este o caracteristică măsurabilă care poate lua mai multe valori. Spre exemplu, venitul unei persoane, vârsta, nivelul de satisfacție al clienților.
Rolul variabilelor: Variabilele sunt elementele centrale ale analizei datelor, definind relațiile, tendințele și corelațiile care pot fi observate în cadrul unui studiu.
3.1.4 Date statistice
Formele sau nivelurile concrete ale caracteristicilor statistice sunt denumite variante, valori sau date și diferă de la o unitate la alta (sau în timp, în cazul aceleiași unități) sub influența unui complex de factori.
Datele statistice exprimă valori ale unor caracteristici cantitative ale unităților statistice.
Numărul unităților la care se înregistrează aceeași variantă sau valoare poartă denumirea de frecvență a variantei/valorii respective.
3.1.5 Indicatori statistici
text
3.2 Mărimile relative
text
3.3 Sistematizarea datelor
text
3.4 Indicatorii de nivel
3.4.1 Aplicații
3.4.1.1 1. Media unei serii simple
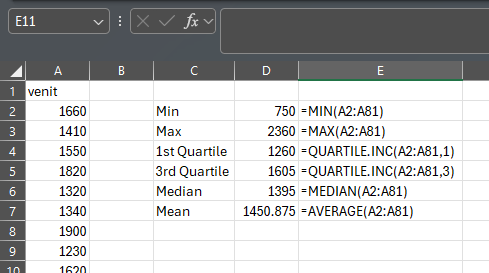
Se cunosc date privind veniturile salariale lunare (în lei/lună) ale celor 80 de angajați din firma M. Caracteristicile serie sunt prezentate în tabelul următor și ne propunem realizarea acestei analize descriptive prin cele 4 platforme software.
grupe de venit (lei)
\(n_i\)
\(h_i\)
\(x_i\)
\(x_i n_i\)
\(N_i\)^
0 – 1000
6
300
850
5100
6
interval quartila inferioară
1001 – 1300
24
300
1150
27600
30
interval median
1301 – 1600
30
300
1450
43500
60
interval quartila superioară
1601 – 1900
12
300
1750
21000
72
1901 – 2200
5
300
2050
10250
77
2201 – \(\inf\)
3
300
2350
7050
80
total
80
-
-
114500
Să se determine venitul salarial mediu lunar al angajaților firmei.
3.4.1.1.1 Rezolvare prin R
# incarcarea datelor "venit.csv"venit<-read.csv("date/venit.csv", head =T)# o vizualizare succinta a datelorhead(venit)
3.4.1.2 2. Gruparea datelor - construirea seriilor de distribuție
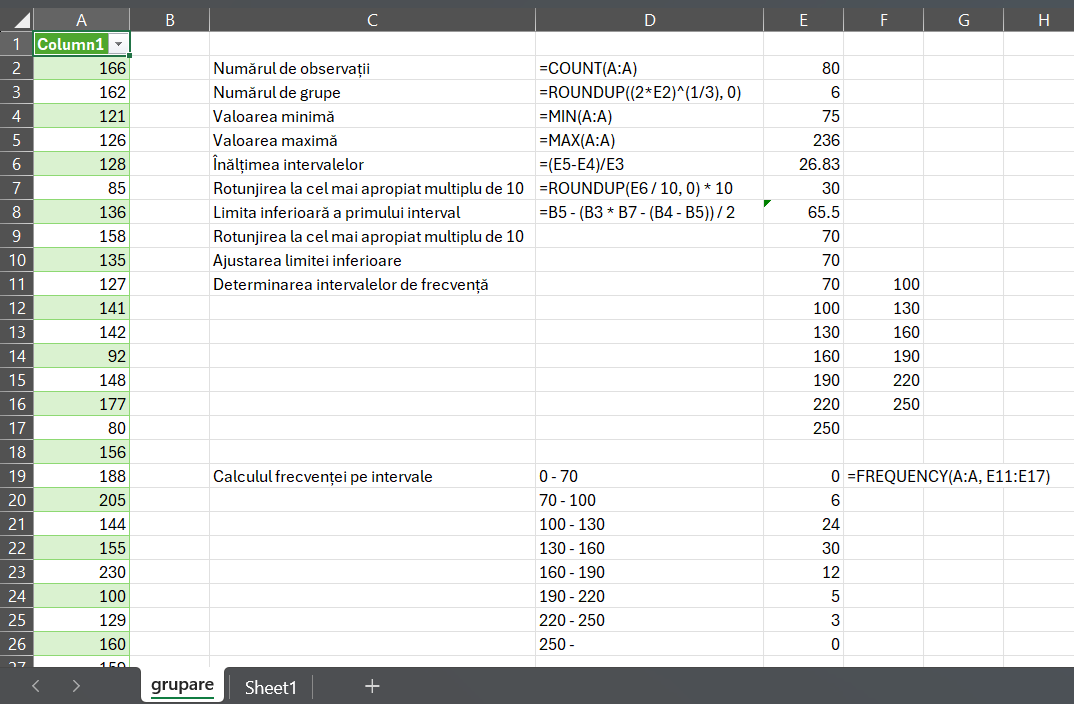
Exemplu: A fost efectuată o cercetare privind mărimea (măsurată pe baza numărului de salariați) a 80 de firme industriale din orașul M. Datele referitoare la numărul de salariați înregistrat în cursul observării sunt următoarele:
166
162
121
126
128
85
136
158
135
127
141
142
92
148
177
80
156
188
205
144
155
230
100
129
160
159
105
150
110
98
182
102
128
198
115
122
124
163
130
133
132
150
75
206
149
170
112
142
119
151
134
224
135
236
126
175
215
130
121
128
190
156
108
143
218
172
180
120
169
129
123
156
142
127
133
146
139
140
138
138
3.4.1.2.1 Rezolvare prin R
# incarcarea datelegrupare<-read.csv("date/grupare.csv", head =F)head(grupare)
V1
1 166
2 162
3 121
4 126
5 128
6 85
# numarul de observatiinobs<-length(grupare$V1)nobs
# rotunjirea la o valoare superioară a intervaluluih<-ceiling(h/10)*10h
[1] 30
# limitele intervalelor de gruparex1_inf<-xmin-(g*h-(xmax-xmin))/2x1_inf
[1] 65.5
# rotunjirea la o valoare superioară a limitei inferioarex1_inf<-ceiling(x1_inf/10)*10x1_inf
[1] 70
# dacă limita inferioară nu cuprinde valoarea minimă se reajustează limita inferioarăif(x1_inf>xmin){x1_inf<-(floor(x1_inf/10)-1)*10}# determinarea intervalelor de frecventelimite_intervale<-seq(from =x1_inf, to =250, by =h)grupare$interval<-cut(grupare$V1, breaks =limite_intervale)library(dplyr)
Attaching package: 'dplyr'
The following objects are masked from 'package:stats':
filter, lag
The following objects are masked from 'package:base':
intersect, setdiff, setequal, union
Prin gospodărie se înțelege grupul de două sau mai multe persoane care locuiesc împreună în mod obișnuit, având, în general, legături de rudenie și care se gospodăresc (fac menajul) în comun, participând în totalitate sau parțial la formarea veniturilor și la cheltuirea lor. Persoana care nu aparține de o gospodărie și care declară că locuiește și se gospodărește singură se consideră gospodărie formată dintr-o singură persoană. Se consideră membri ai gospodăriei și persoanele plecate din localitate pentru o perioadă mai mare de 6 luni, care se află în țară sau străinătate, dacă acestea păstrează legături familiale cu gospodăria↩︎